Lillian Lee, Choice 2019 Symposium "Wisdom from Words: Insight from Language and Text Analysis", draft/work in progress
This URL: https://confluence.cornell.edu/display/~ljl2/Choice2019
Setting: what makes language type A different from type B?
Applications I and my co-authors have worked on:
- etc
For various reasons, including an eye towards deploying applications, we ultimately evaluate our hypothesis with prediction even though we are personally interested and invested in understanding what underlies the phenomenon being considered.
Some features I like
(in a long line of LiWC-like lexicons) Chenhao Tan's list of hedging phrases, such as "I suspect", "raising the possibility": [README] [list itself]
- language models, which assign probabilities P(x) to words, sentences or text units.
These are great for similarity, distinctiveness, visualization.Monroe et al's "Fightin words": what makes two "languages" different?
Slides and handout from Cristian Danescu-Niculescu-Mizil and my class "NLP and social interaction" : [ pptx ] [ pdf ] [handout]

- Similarity measured on the most frequent words ("stop words") only vs. on the content words
How similar are two language models? The standard measure is the cross-entropy: - Σ p( x) log( q(x)) ; a variant is the KL divergence, Σ p(x) log( p(x) / q(x)) = the cross entropy of p(x) and q(x) minus the entropy of p(x) Similarity of each of A or B to a baseline of "regular" or "null hypothesis" language.
Distributional similarity (word embeddings are the modern version)
Here's a figure from 1997 about ideas from the early 90's:

For references, see the word embeddings section later in this document


Some others I don't expect to have time to discuss
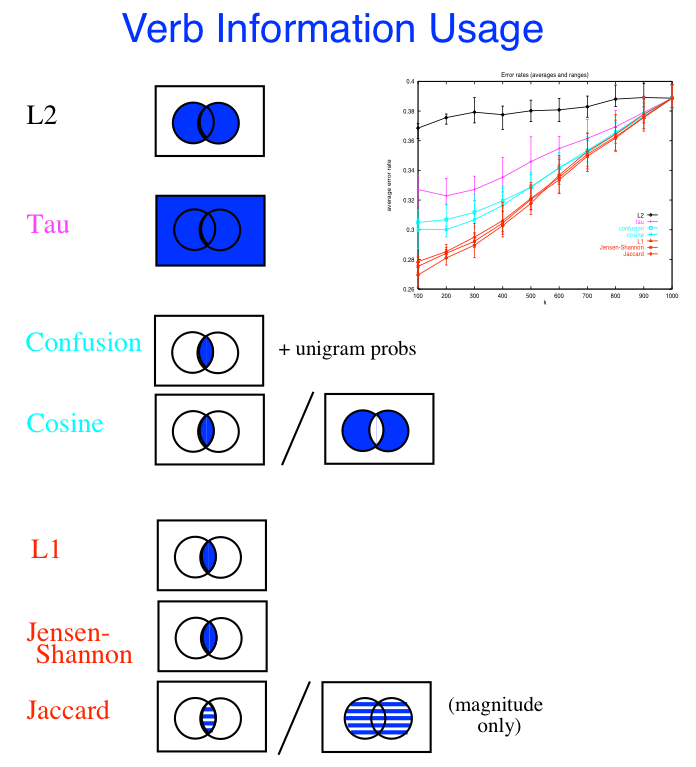
... and one feature that I both like and drives me crazy: length
How do we proceed during the age of deep learning, where, for prediction, we don't need to (aren't supposed to) worry about features anymore?