Lillian Lee, Choice 2019 Symposium "Wisdom from Words: Insight from Language and Text Analysis"
This URL:
Some features I like
https://confluence.cornell.edu/display/~ljl2/Choice2019
Setting: what makes language type A different from type B?
For various reasons, including an eye towards deploying applications, we ultimately evaluate our hypothesis with prediction even though we are personally interested and invested in understanding what underlies the phenomenon being considered.
| Expand | |||||
|---|---|---|---|---|---|
| |||||
| |||||
| Expand | |||||
(in a long line of LiWC-like lexicons) Chenhao Tan's list of hedging phrases, such as "I suspect", "raising the possibility": [README] [list itself] Expand | | ||||
|





, Vlad Niculae, Cristian Danescu-Niculescu-Mizil, Lillian Lee. 2016. "Winning arguments: Interaction dynamics and persuasion strategies in good-faith online discussions." Proc. of WWW |
. Abstract: Changing someone's opinion is arguably one of the most important challenges of social interaction. The underlying process proves difficult to study: it is hard to know how someone's opinions are formed and whether and how someone's views shift. Fortunately, ChangeMyView, an active community on Reddit, provides a platform where users present their own opinions and reasoning, invite others to contest them, and acknowledge when the ensuing discussions change their original views. In this work, we study these interactions to understand the mechanisms behind persuasion. We find that persuasive arguments are characterized by interesting patterns of interaction dynamics, such as participant entry-order and degree of back-and-forth exchange. Furthermore, by comparing similar counterarguments to the same opinion, we show that language factors play an essential role. In particular, the interplay between the language of the opinion holder and that of the counterargument provides highly predictive cues of persuasiveness. Finally, since even in this favorable setting people may not be persuaded, we investigate the problem of determining whether someone's opinion is susceptible to being changed at all. For this more difficult task, we show that stylistic choices in how the opinion is expressed carry predictive power.
Fu, Liye, Cristian Danescu-Niculescu-Mizil and Lillian Lee. 2016. Tie-breaker: Using language models to quantify gender bias in sports journalism. IJCAI workshop on NLP Meets Journalism Best paper award. Abstract: Gender bias is an increasingly important issue in sports journalism. In this work, we propose a language-model-based approach to quantify differences in questions posed to female vs. male athletes, and apply it to tennis post-match interviews. We find that journalists ask male players questions that are generally more focused on the game when compared with the questions they ask their female counterparts. We also provide a fine-grained analysis of the extent to which the salience of this bias depends on various factors, such as question type, game outcome or player rank.
Hessel, Jack and Lillian Lee. 2019. Something’s Brewing! Early Prediction of Controversy-causing Posts from Discussion Features. Proc. of NAACL. Abstract: Controversial posts are those that split the preferences of a community, receiving both significant positive and significant negative feedback. Our inclusion of the word "community" here is deliberate: what is controversial to some audiences may not be so to others. Using data from several different communities on www.reddit.com, we predict the ultimate controversiality of posts, leveraging features drawn from both the textual content and the tree structure of the early comments that initiate the discussion. We find that even when only a handful of comments are available, e.g., the first 5 comments made within 15 minutes of the original post, discussion features often add predictive capacity to strong content-and-rate only baselines. Additional experiments on domain transfer suggest that conversation-structure features often generalize to other communities better than conversation-content features do.
|
| Expand | ||
|---|---|---|
| ||
https://www.flickr.com/photos/hyku/3614261299/in/photostream/ http://pixabay.com/en/twitter-tweet-twitter-bird-312464/ http://commons.wikimedia.org/wiki/File:Greek_uc_delta.png, colorized Screen shot from video at http://covertheathlete.com/ |
Some features/technologies I like
| Expand | |||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
The Cornell Conversational Analysis ToolkitFeatures for: linguistic coordination, politeness strategies, conversation motifs, conversation graphs Datasets: Wikipedia talk page conversations that (do not) become derailed by personal attacks; dialogs from movie scripts; UK Parliamentary question-answer pairs; Supreme Court oral arguments; Wikipedia talk pages conversations; post-tennis-match press interviews; reddit conversations. Chenhao Tan's list of hedging phrases, such as "I suspect", "raising the possibility":This is in the long line of LIWC-like lexicons. [README] [list itself]
Language models, which assign probabilities P(x) to words, sentences or text units after being trained on some language sample.These are great for similarity, distinctiveness, visualization.
Distributional similarity (word embeddings are the modern version)Here's a figure from 1997 about ideas from the early 90's: For references, see the word embeddings section later in this document
| (Some others that I don't expect to have time to discuss) |


| |
|

| Expand | ||
|---|---|---|
| ||
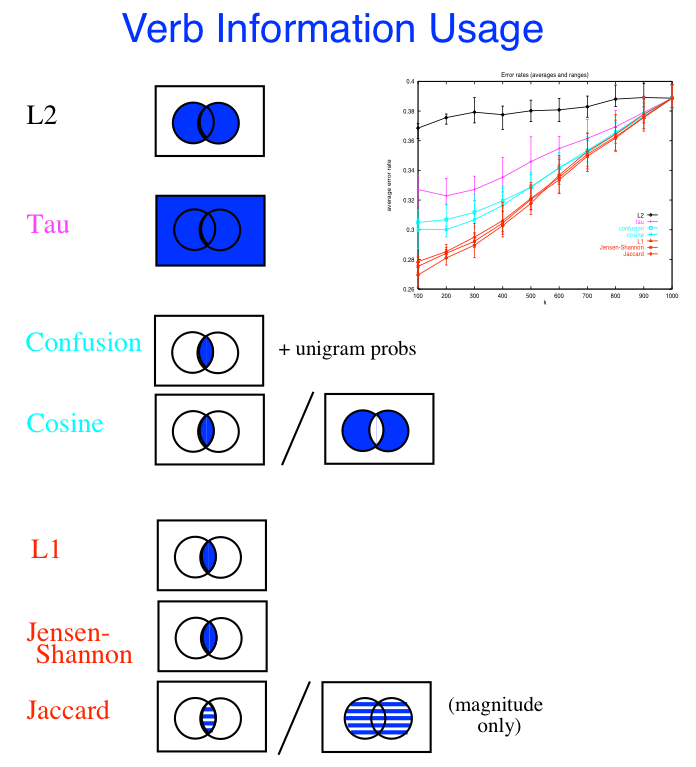
Lee, Lillian. 1999. Measures of distributional similarity. Proc. of the ACL, 25--32 |
... and one feature that I both like and drives me crazy: length
| Expand |
|---|
It represents an intuitively slightly ridiculous null hypothesis that often works surprisingly well as a feature, most likely because it correlates with a lot of other features of interest. ExampleExamples: (to be inserted) |
...
A feature-effectiveness test that's caught my eye
Wang, Zhao and Aron Culotta, When do Words Matter? Understanding the Impact of Lexical Choice on Audience Perception using Individual Treatment Effect Estimation. AAAI 2019. [code]
How do we proceed during the age of deep learning, where, for prediction, we don't need to (aren't supposed to) worry about features anymore?
| Expand | ||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
BERT vs Comparison of hand-crafted features, controversy paper
less hidden against deep learning on predicting controversial social-media posts
star = best in column; circle = performance within 1% of the best in column. Columns: different sub-reddits.
Question/proposal : where is the word embedding version of LIWC? ("Can we BERT LIWC?").
Language modeling = the bridge?Note that the basic units might be characters or unicode code points ("names of character") instead of words.
|

{kind=link}
not hidden