Comparison of hand-crafted features against deep learning on predicting controversial social-media posts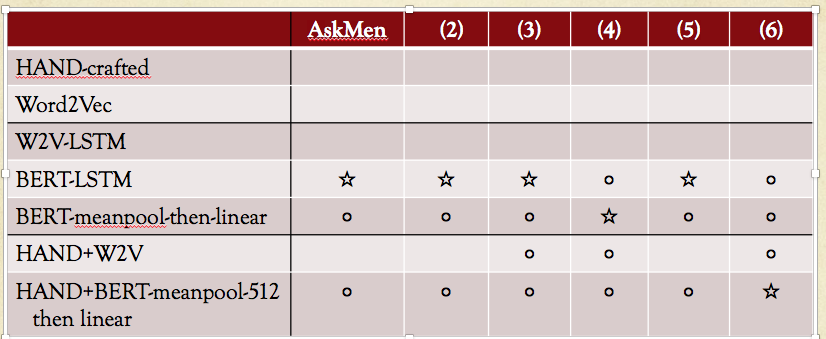
star = best in column; circle = performance within 1% of the best in column. Columns: different sub-reddits. | Expand |
|---|
| Image adapted from Table 2 of Hessel, Jack and Lillian Lee. 2019. Something’s Brewing! Early Prediction of Controversy-causing Posts from Discussion Features. Proc. of NAACL. HAND = "for the title and text body separately, length, type-token ratio, rate of first-person pronouns, rate of second-person pronouns, rate of question-marks, rate of capitalization, and Vader sentiment. Combining the post title and post body: number of links, number of Reddit links, number of imgur links, number of sentences, Flesch-Kincaid readability score, rate of italics, rate of boldface, presence of a list, and the rate of word use from 25 Empath wordlists. |
| Anchor |
|---|
| word-embeddings |
|---|
| word-embeddings |
|---|
|
Word embeddings - now contextual/polysemy-aware! Question/proposal : where is the word embedding version of LIWC? ("Can we BERT LIWC?").
| Expand |
|---|
| title | Some work in this direction |
|---|
| Fast, Ethan, Binbin Chen, Michael S Bernstein. Lexicons on demand: Neural word embeddings for large-scale text analysis. IJCAI 2017. Abstract: Human language is colored by a broad range of topics, but existing text analysis tools only focus on a small number of them. We present Empath, a tool that can generate and validate new lexical categories on demand from a small set of seed terms (like “bleed” and “punch” to generate the category violence). Empath draws connotations between words and phrases by learning a neural embedding across billions of words on the web. Given a small set of seed words that characterize a category, Empath uses its neural embedding to discover new related terms, then validates the category with a crowd-powered filter. Empath also analyzes text across 200 built-in, pre-validated categories we have generated such as neglect, government, and social media. We show that Empath’s data-driven, human validated categories are highly correlated (r=0.906) with similar categories in LIWC.
|
Language modeling = the bridge?Note that the basic units might be characters or unicode code points ("names of character") instead of words. | Expand |
|---|
| title | Recommendations from Jack Hessel and Yoav Artzi, Cornell |
|---|
| Thanks to Jack Hessel and Yoav Artzi for the below. Paraphrasing errors are my own. The best off-the-shelf language model right now (caveat: this is a very fast-moving field) is the 12-or-so layer GPT-2, where GPT stands for Generative Pre-Training. [code] [(infamous) announcement] [hugging face's reimplementation of pre-trained GPT-2] But a single-layer LSTM trained from scratch, with carefully chosen hyperparameters, is still often a very strong baseline, especially with small data (around 10K samples). Both BERT and GPT seems to transfer well via fine-tuning to small new datasets, at least in expert hands. [code] [Colab] [hugging face's reimplementation of pre-trained BERT] [announcement]The Giant Language model Test Room (GLTR) can be used for analyzing what a neural LM is doing, although its stated purpose is to enable "detect automatically generated text". | Expand |
|---|
| Devlin, Jacob, Ming-wei Chang, Kenton Lee, Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proc. of NAACL. [arXiv version] Rush, Sasha, with VIncent Nguyen and Guillaume Klein. April 3, 2018. The annotated transformer — interpolates code line-by-line for Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin, 2017. Attention is all you need. Proc. of NIPS. [arxiv version] Radford, Alec, Wu, Jeffrey, Child, Rewon, Luan, David, Amodei, Dario, Sutskever, Ilya. 2019. Language models are unsupervised multitask learners. Manuscript. (The GPT-2 paper) |
|
|